C++ jargon: std::hardware_destructive_interference_size
This series gives a brief introduction to C++ feature/abbreviation/concept with actual usage.
Background
This constant is just a portable (platform-neutral) way to obtain the size of L1 cache line, so there is nothing interesting to explain about. However, the term “hardware destructive interference” requires some explanation. In here, the term refers to a more commonly known concept as “false-sharing”. The upcoming sections require basic knowledge on cache and multithreading.
False-Sharing
False-sharing is a harmful pattern to performance that happens in a multicores system where each core has its own L1 cache. Under such system, caches are designed to remain coherent so update of memory by one core is properly broadcasted* to other cores. In another word, the data in all the L1 caches are always correct, even when they are pointing to the same memory. So, let’s say we have two cores Core 1 and Core 2 both accessing the same integer alpha, initialized as 1.
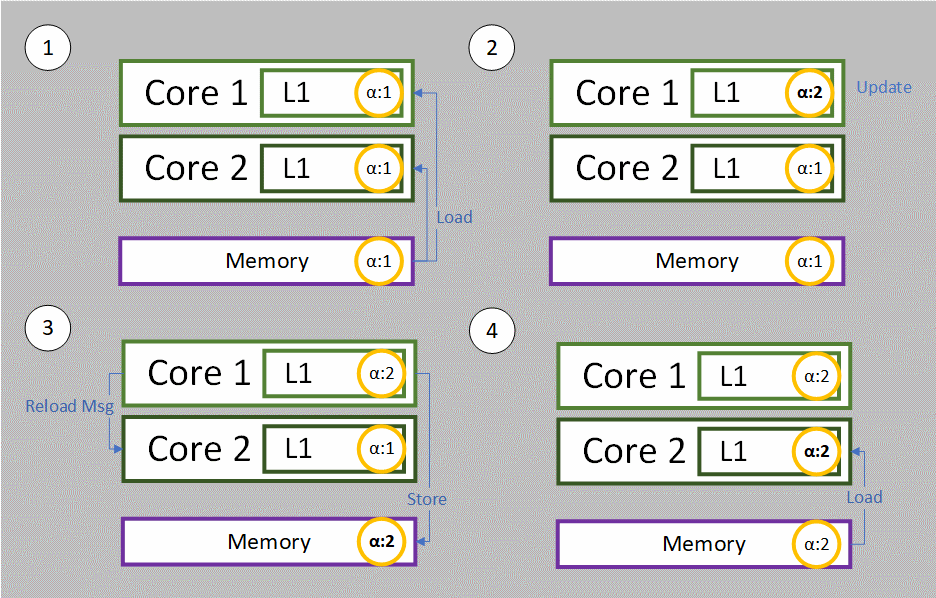
- Both cores will load alpha into their cache first which is at value 1.
- Then we increment alpha to 2 by Core 1.
- After storing the new alpha back to memory, Core 1 will issue a message and notify Core 2 that it must reload its cache, because alpha is no longer 1.
- Core 2 reload alpha again from memory into its cache for use.
So far it makes sense. However, cache does not work in terms of one integer or one piece of memory, it works on “cache line”, which is usually a power of 2 word size (for example 64 bytes). Let’s say the memory we are accessing is a struct Pair which contains two integers alpha and beta. Core 1 will amend alpha and Core 2 will just read beta.
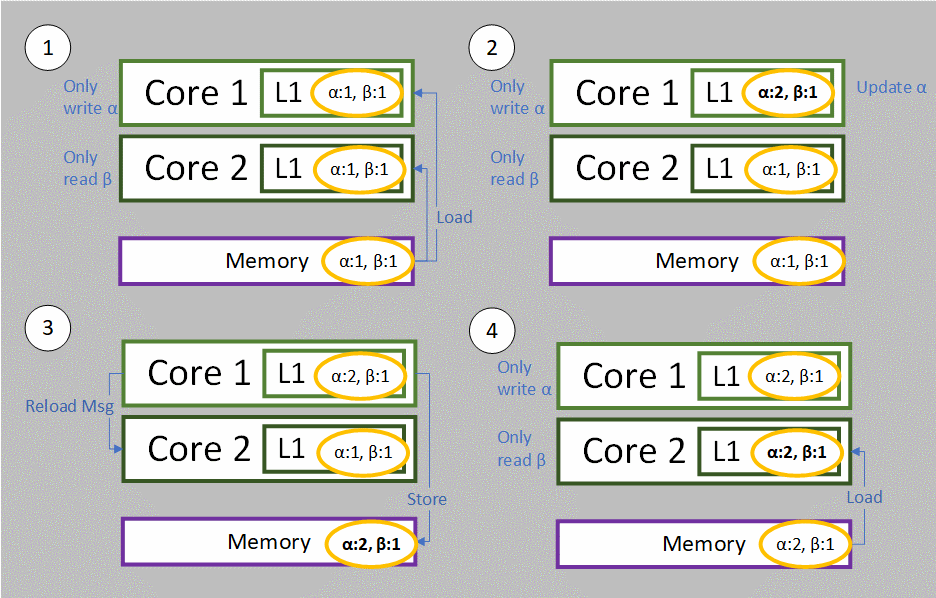
- Both cores will load the whole cache line starting at Pair into their cache first.
- Then we increment alpha to 2 by Core 1.
- After storing the new alpha back to memory, Core 1 will issue a message and notify Core 2 that it must reload its cache line, because the cache line containing alpha is no longer valid.
- Core 2 reload the whole cache line starting at Pair again from memory into its cache for use.
- But actually Core 2 only wants to read beta which is already valid at the first load
These two cores look like they are working completely independent from each other. But as the data exist on the same cache line, the cache system will reload the cache line for Core 2 just as what we suggested before. There is nothing wrong, but it degrades performance, because the cache line reload on Core 2 is not necessary. And reloading cache line means stalling the processor to wait for the memory to be transferred from the main memory to cache again.
I believe the “false” here means we have an “incorrect” sharing of the cache line, as this pattern won’t occur if we have alpha and beta on a different cache lines which are not shared at the very beginning.
*The broadcast is done by messaging between caches in the MESI (Modified, Exclusive, Shared, Invalid) protocol, which will not be discussed here.
Example
I am building a job system for my own toy game engine. The implementation is not important in the context here, we can just imagine job as a function pointer waiting to be executed. Basically, there are multiple workers running on multiple threads that keep grabbing jobs from a contiguous memory allocated job queue, a very typical producer-consumer pattern. Job itself is a concurrently-accessed object, Job 1 can be accessed and amended by Core 1 while Job 2 is accessed by Core 2.
struct alignas(std::hardware_destructive_interference_size) Job
{
void (*m_pFunction)(const void*) = nullptr;
void* m_pData = nullptr;
Job* m_pParent = nullptr;
std::atomic_int32_t m_iUnfinished = {0};
};
Here the total size of Job’s members are 8 + 8 + 8 + 4 = 28 bytes, and on my x64 computer the cache line is 64 bytes. It means that we can fit two and almost a half Job in one cache line, so false-sharing is destined to occur. By using alignas(std::hardware_destructive_interference_size), Job is now the size of my L1 cache line, which is 64 bytes. So false-sharing is avoid at the cost of increasing memory footprint.
To detect false-sharing, we should keep this pattern at mind and watch out when we are programming multithreaded code. Second is of course to profile. Profile the program’s rate of cache misses and study it closely.
Reference
- I suggest spending a few minutes reading through the original proposal. It describes how programmers obtain the cache line size before this constant exists and why it is not the best practice: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0154r1.html
- This is a very technical presentation on cache coherency by Naughty Dog’s Programming Director Christian Gyrling, putting it here just to remind fellow game programmers cache matters: http://www.swedishcoding.com/wp-content/uploads/2017/11/Cache-Coherency-and-Multi-Core-Programming.pdf
- C++ Reference Page: https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
Remarks
There is also a std::hardware_constructive_interference_size which promotes “true-sharing”, but it won’t be discussed here.